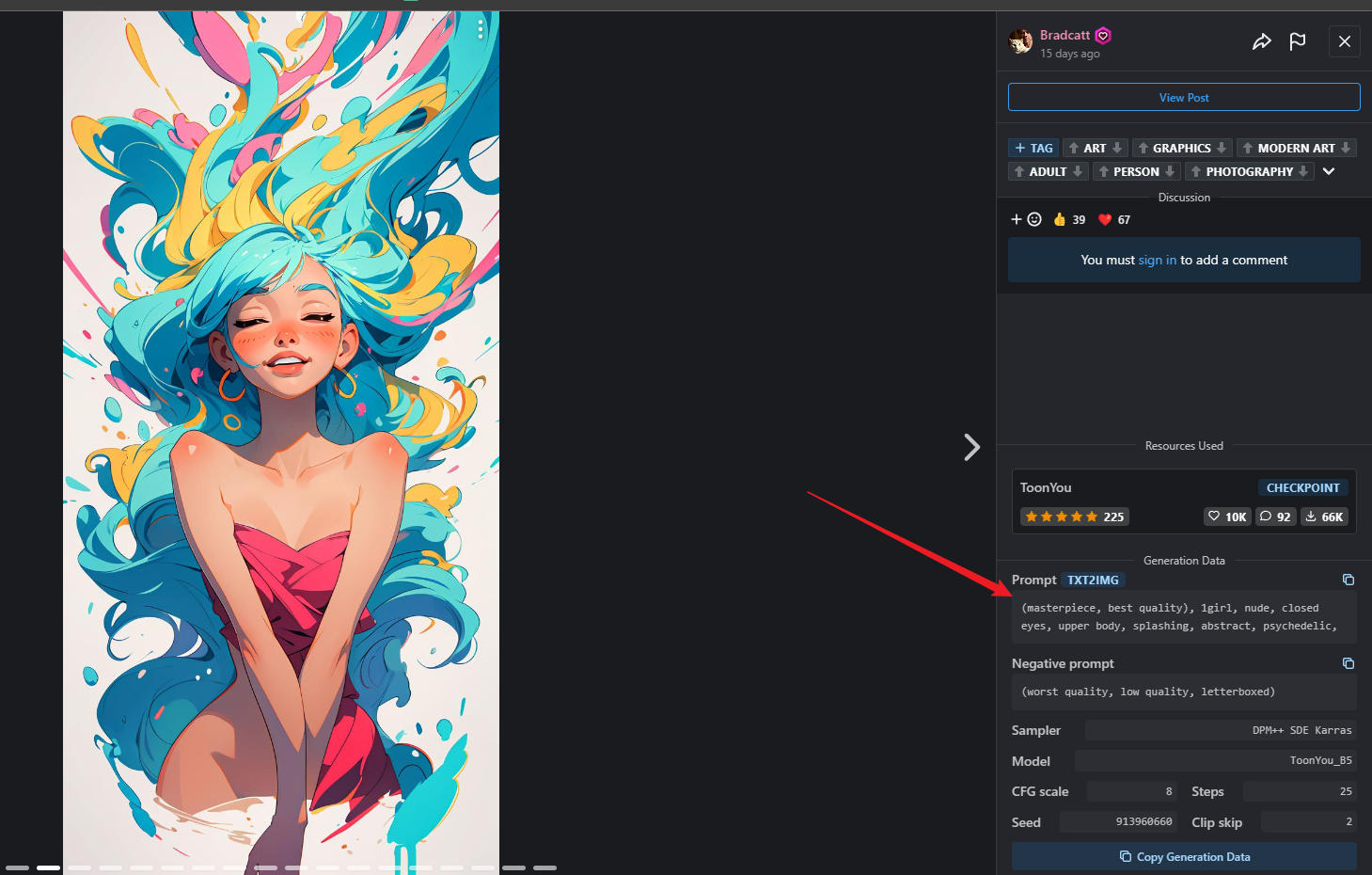
Stable Diffusion 各种模型
模型常见格式介绍
刚接触 huggingface 模型仓库的同学难免会被一堆文件感到困惑,搞不清自己到底该下那个文件,所以在这里讲下这些仓库的常见构成

模型训练作者一般都会上传 ckpt 格式,它就是 webui 适用的格式,一般来说我们只需找到 ckpt 格式的模型文件下载即可。
模型文件的后缀为 .ckpt 或者 .safetensors
.ckpt: 包含 Python 代码的压缩文件,对于 Python 语言的程序来说很通用方便,缺点是文件很大,一般 2-8G。它的文件是用 pickle 序列化的,这意味着它们可能包含恶意代码,如果你不信任模型来源,加载 .ckpt 文件可能会危及你的安全。.safetensors: 只包含生成所需的数据,不包含代码,一般只有几十到几百 M,加载文件也更安全和快速。它的文件是用 numpy 保存的,这意味着它们只包含张量数据,没有任何代码,加载.safetensors文件更安全和快速。
Safetensors
huggingface 后来又推出了 safetensors 格式,旨在取代前面介绍的格式,使用方法上与 ckpt 格式类似,也是下载到 webui 的 model 文件夹下即可(如果 webUI 加载不出 safetensors 格式模型,可能是 webui 版本过旧,使用 git pull 更新即可)
比 ckpt 格式加载速度更快更安全
safetensors 直接可以在 webUI 中原生调用,无需转换格式
大模型/底模型
属于基础模型也叫预调模型

首先介绍的是大模型,是 SD 能够绘图的基础模型。安装完 SD 软件后,必须搭配基础模型才能使用。不同的基础模型,其画风和擅长的领域会有侧重。
Lora 模型
属于微调模型,如果把基础模型比喻作一座房子的地基,那么 Lora 模型就好比在这个地基上盖起来的房子。我们通常也称为微调模型,用于满足一种特定的风格,或指定的人物特征属性。在数据相似度非常高的情形下,使用微调模型,可以节省大量的训练时间和训练资源,就可以产出我们需要的结果。
要想获得不同的 lora,可以是到网络上 C 站或国内的AI图站下载。下载后的 lora 文件直接放到 Stable Diffusion 安装目录的 models 的 lora 目录里。刷新后就可使用。
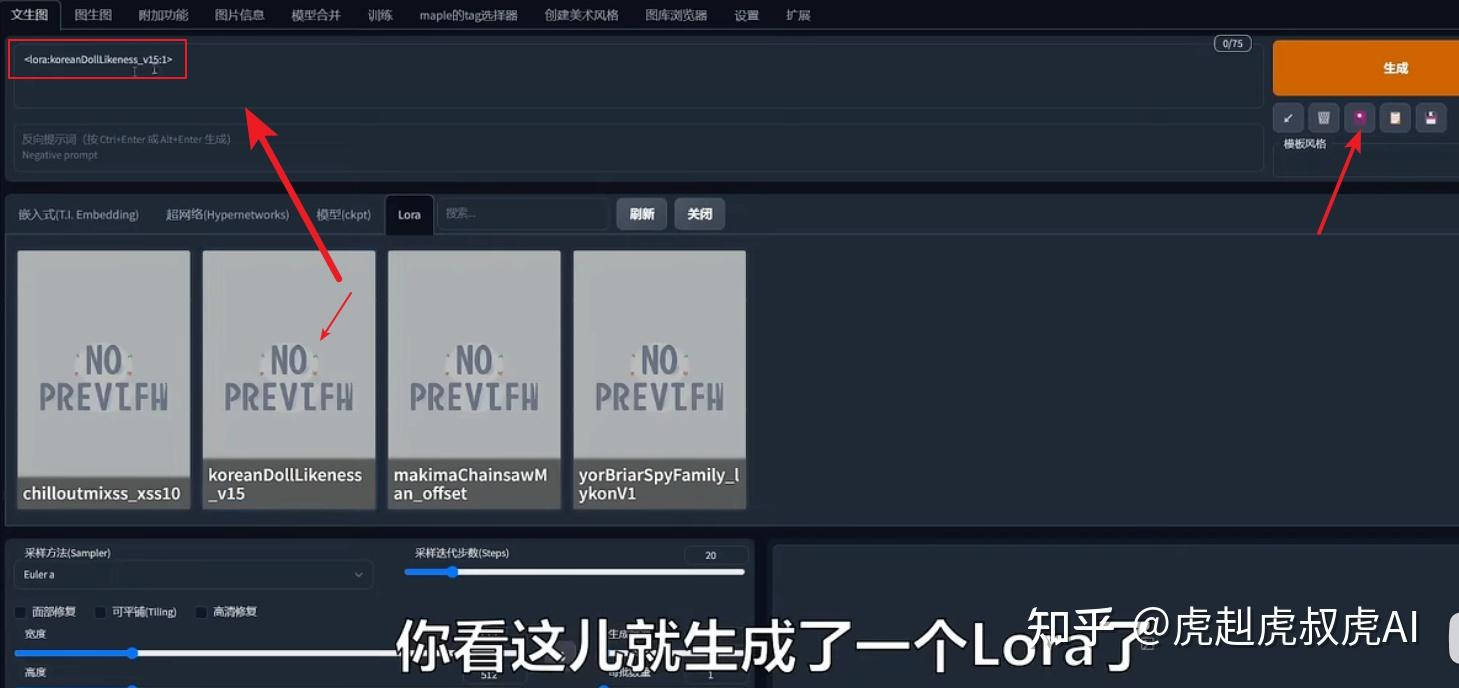
点击 lora 调用按钮后,在 tag 栏就可以看到一个词条,然后再继续编辑描述语即可。

lora 模型也是一般用户可以用来训练的
VAE 美化模型
VAE,全名 Variational autoenconder,中文叫变分自编码器。作用是:滤镜+微调。

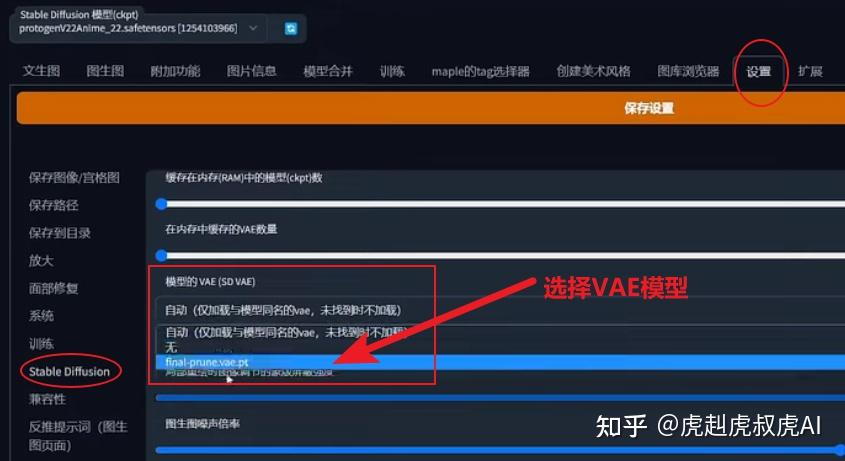

有的大模型是会自带VAE的,比如我们常用的Chilloutmix。如果再加VAE则可能画面效果会适得其反。
LyCORIS 模型
此类模型也可以归为 Lora 模型,也是属于微调模型的一种。一般文件大小在340M左右。不同的是训练方式与常见的lora不同,但效果似乎会更好不少。
但要使用此类微调模型,需要先安装一个locon插件,直接将压缩包解压后放到 StableDiffusion 目录的extensions 目录里。
https://github.com/KohakuBlueleaf/a1111-sd-webui-lycoris
v1-5-pruned-emaonly 模型
启动后的界面,可以看到默认是 v1-5-pruned-emaonly 的模型:

根据 huggingface 的介绍,v1-5-pruned 版本是基于 v1-2 版本 fine tune 得到,提升了 CFG 采样
在介绍文档里,可以看到,权重分为2种:
- v1-5-pruned-emaonly.ckpt - 4.27GB, ema-only weight. uses less VRAM - suitable for inference
- v1-5-pruned.ckpt - 7.7GB, ema+non-ema weights. uses more VRAM - suitable for fine-tuning
可以看到 emaonly 的区别在于:它的规模更小,使用更少的显存,适合做推理。而 ema+non-ema 的规模更大,使用更多显存,适合做调优。
Checkpoint 文件就是 Stable Diffusion 的权重。
nonema 和 ema 的区别
EMA和non-EMA模型有什么不同?
EMA=exponential moving average
想训练模型就用 EMA 版 只想出图就用 non-EMA 版
安装 Stable Diffusion 2.0
SD 2.0 使用了更大的text encoder(可以提升图片质量),并调整默认图片大小为768 x 768像素。
首先在 huggingface 下载 stable-diffusion-2 版本,并放入目录 stable-diffusion-webui/models/Stable-diffusion/ 下:
wget https://huggingface.co/stabilityai/stable-diffusion-2-1/blob/main/v2-1_768-nonema-pruned.safetensors
然后即可在 web UI 里进行使用。
由于SD 2.0 是在 768 x 768 的图片上生成的,所以确保设置的 width 与 height 同样为 768。一般使用 DPM++2M Karras 采样器 +30 个采样步,可以满足大部分场景。
在转换 SD v1 到 v2 时,需要注意的点:
- v1 生成的图片大小为 512 x 512,v2 生成的图片大小为 768 x 768。虽然 v2 设计为可以生成 512 x 512 以及 768 x 768 的图片,但是早期测试看起来512 x 512的图片不够好
- 不要在 v2 里复用 v1 的 prompt。在 v1 里表现很好的 prompt 可能在 v2 里不太适用。这个结果也是合理的,因为 v2 使用了更大的 OpenClip H/14 的分词器(差不多是 v1 模型的 6 倍)。并且是从头开始训练的。
- v2 的图片一般更真实。例如 “Ink drips portrait”,在 v2 里更真实,而在 v1 里更有艺术感
- 如果一定要用 v1 的 prompt,可以使用 prompt converter 来做转换。它的工作原理是:先用 v1 的 prompt生成图,然后使用 CLIP interrogator 2 从图中提取 prompt 词。它可以高效地给出模型如何描述图片的词汇
- 使用更长的 prompt(更多的 prompt 词),以及更明确的描述,在 v2 里更为适用
总的来说:SD 2.0 可以生成更高质量的图片,并更符合 prompt 词的结果。
civitai 模型库
Civitai 是一个提供AI艺术资源分享和发现的平台,旨在帮助用户轻松探索并使用各类AI艺术模型。平台用户可以上传和分享自己用数据训练的AI自定义模型,或者浏览和下载其他用户创建的模型。这些模型可以与AI艺术软件一起使用,生成个性化、独特的艺术作品。
https://civitai.com/ 里面包含了各种预训练的模型
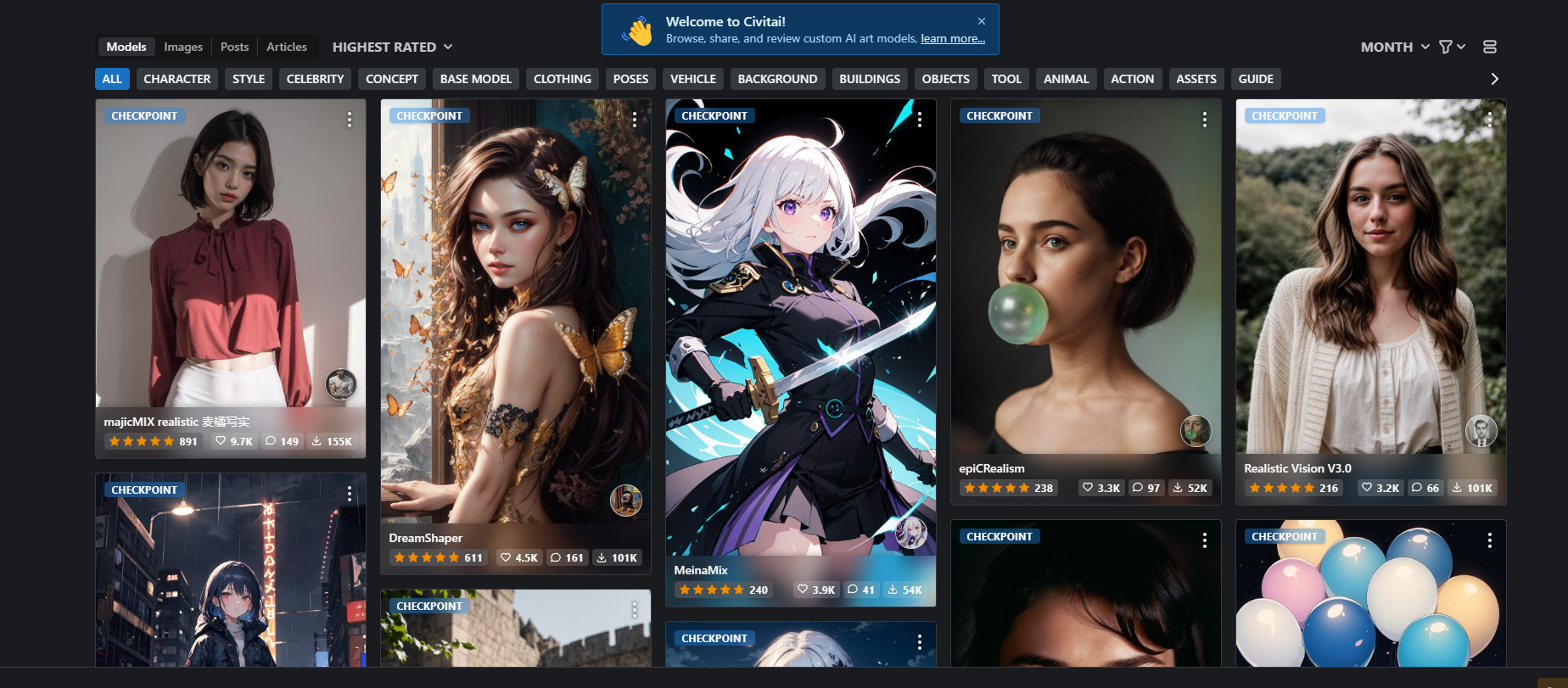
例如这里标识的是 CHECKPOINT,说明这个模型不需要使用基座模型,直接就能用

可以到官方提供的图片里找到相应的参数